Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/12/23 21:47:41 INFO SparkContext: Running Spark version 2.3.0
21/12/23 21:47:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
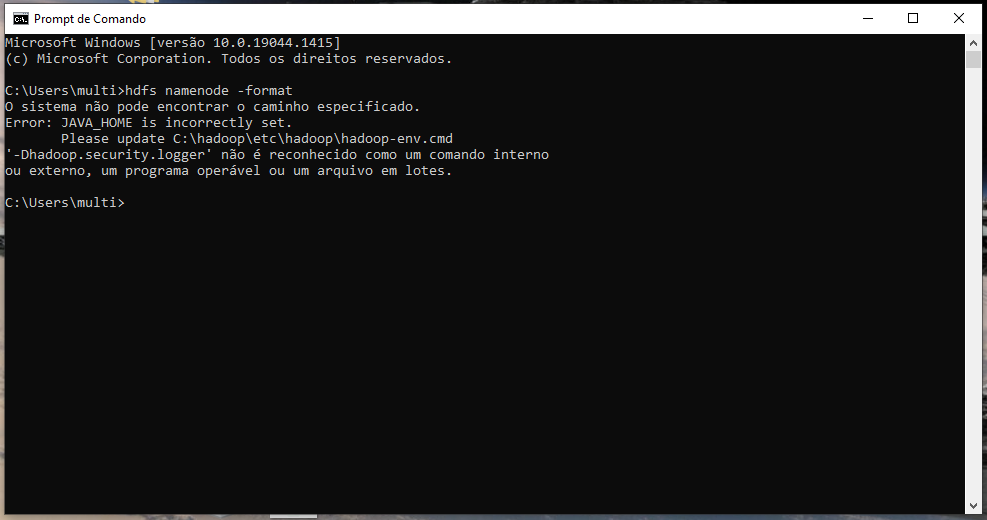
21/12/23 21:47:41 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:378)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:393)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:386)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116)
at org.apache.hadoop.security.Groups.<init>(Groups.java:93)
at org.apache.hadoop.security.Groups.<init>(Groups.java:73)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2464)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:292)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2486)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:930)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:921)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:921)
at com.packt.JavaDL.App.EDA.ExploratoryDataAnalysis.main(ExploratoryDataAnalysis.java:21)
21/12/23 21:47:41 INFO SparkContext: Submitted application: Bitcoin Preprocessing
21/12/23 21:47:41 INFO SecurityManager: Changing view acls to: multi
21/12/23 21:47:41 INFO SecurityManager: Changing modify acls to: multi
21/12/23 21:47:41 INFO SecurityManager: Changing view acls groups to:
21/12/23 21:47:41 INFO SecurityManager: Changing modify acls groups to:
21/12/23 21:47:41 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(multi); groups with view permissions: Set(); users with modify permissions: Set(multi); groups with modify permissions: Set()
21/12/23 21:47:42 INFO Utils: Successfully started service 'sparkDriver' on port 62101.
21/12/23 21:47:42 INFO SparkEnv: Registering MapOutputTracker
21/12/23 21:47:42 INFO SparkEnv: Registering BlockManagerMaster
21/12/23 21:47:42 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
21/12/23 21:47:42 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
21/12/23 21:47:42 INFO DiskBlockManager: Created local directory at C:\Users\multi\AppData\Local\Temp\blockmgr-03864a3a-ed21-4c0a-8b17-c5f89b651b5e
21/12/23 21:47:42 INFO MemoryStore: MemoryStore started with capacity 4.6 GB
21/12/23 21:47:42 INFO SparkEnv: Registering OutputCommitCoordinator
21/12/23 21:47:42 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/12/23 21:47:42 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://DESKTOP-2S65B7B:4040
21/12/23 21:47:42 INFO Executor: Starting executor ID driver on host localhost
21/12/23 21:47:42 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62102.
21/12/23 21:47:42 INFO NettyBlockTransferService: Server created on DESKTOP-2S65B7B:62102
21/12/23 21:47:42 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
21/12/23 21:47:42 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, DESKTOP-2S65B7B, 62102, None)
21/12/23 21:47:42 INFO BlockManagerMasterEndpoint: Registering block manager DESKTOP-2S65B7B:62102 with 4.6 GB RAM, BlockManagerId(driver, DESKTOP-2S65B7B, 62102, None)
21/12/23 21:47:42 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, DESKTOP-2S65B7B, 62102, None)
21/12/23 21:47:42 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, DESKTOP-2S65B7B, 62102, None)
21/12/23 21:47:42 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('temp/').
21/12/23 21:47:42 INFO SharedState: Warehouse path is 'temp/'.
21/12/23 21:47:42 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
Exception in thread "main" java.lang.reflect.InaccessibleObjectException: Unable to make field private transient java.lang.String java.net.URI.scheme accessible: module java.base does not "opens java.net" to unnamed module @480d3575
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354)
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at java.base/java.lang.reflect.Field.checkCanSetAccessible(Field.java:178)
at java.base/java.lang.reflect.Field.setAccessible(Field.java:172)
at org.apache.spark.util.SizeEstimator$$anonfun$getClassInfo$3.apply(SizeEstimator.scala:336)
at org.apache.spark.util.SizeEstimator$$anonfun$getClassInfo$3.apply(SizeEstimator.scala:330)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at org.apache.spark.util.SizeEstimator$.getClassInfo(SizeEstimator.scala:330)
at org.apache.spark.util.SizeEstimator$.visitSingleObject(SizeEstimator.scala:222)
at org.apache.spark.util.SizeEstimator$.org$apache$spark$util$SizeEstimator$$estimate(SizeEstimator.scala:201)
at org.apache.spark.util.SizeEstimator$.estimate(SizeEstimator.scala:69)
at org.apache.spark.sql.execution.datasources.SharedInMemoryCache$$anon$1.weigh(FileStatusCache.scala:109)
at org.apache.spark.sql.execution.datasources.SharedInMemoryCache$$anon$1.weigh(FileStatusCache.scala:107)
at org.spark_project.guava.cache.LocalCache$Segment.setValue(LocalCache.java:2222)
at org.spark_project.guava.cache.LocalCache$Segment.put(LocalCache.java:2944)
at org.spark_project.guava.cache.LocalCache.put(LocalCache.java:4212)
at org.spark_project.guava.cache.LocalCache$LocalManualCache.put(LocalCache.java:4804)
at org.apache.spark.sql.execution.datasources.SharedInMemoryCache$$anon$3.putLeafFiles(FileStatusCache.scala:152)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$listLeafFiles$2.apply(InMemoryFileIndex.scala:130)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$listLeafFiles$2.apply(InMemoryFileIndex.scala:128)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.listLeafFiles(InMemoryFileIndex.scala:128)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.refresh0(InMemoryFileIndex.scala:91)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.<init>(InMemoryFileIndex.scala:67)
at org.apache.spark.sql.execution.datasources.DataSource.tempFileIndex$lzycompute$1(DataSource.scala:161)
at org.apache.spark.sql.execution.datasources.DataSource.org$apache$spark$sql$execution$datasources$DataSource$$tempFileIndex$1(DataSource.scala:152)
at org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:166)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:392)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:239)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:227)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:174)
at com.packt.JavaDL.App.EDA.ExploratoryDataAnalysis.main(ExploratoryDataAnalysis.java:28)
21/12/23 21:47:42 INFO SparkContext: Invoking stop() from shutdown hook
21/12/23 21:47:42 INFO SparkUI: Stopped Spark web UI at http://DESKTOP-2S65B7B:4040
21/12/23 21:47:42 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/12/23 21:47:42 INFO MemoryStore: MemoryStore cleared
21/12/23 21:47:42 INFO BlockManager: BlockManager stopped
21/12/23 21:47:42 INFO BlockManagerMaster: BlockManagerMaster stopped
21/12/23 21:47:42 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/12/23 21:47:42 INFO SparkContext: Successfully stopped SparkContext
21/12/23 21:47:42 INFO ShutdownHookManager: Shutdown hook called
21/12/23 21:47:42 INFO ShutdownHookManager: Deleting directory C:\Users\multi\AppData\Local\Temp\spark-8ad2da70-9bb2-4785-ba9d-46c6a6ee2282
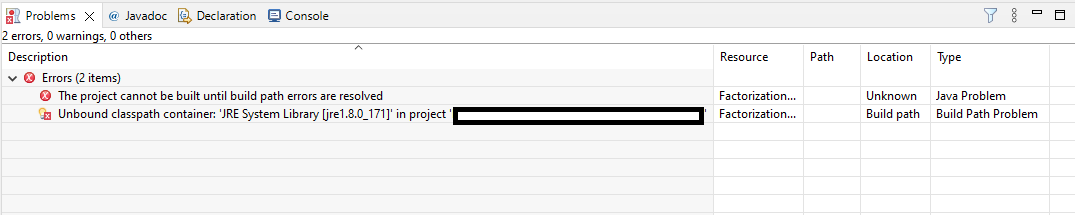
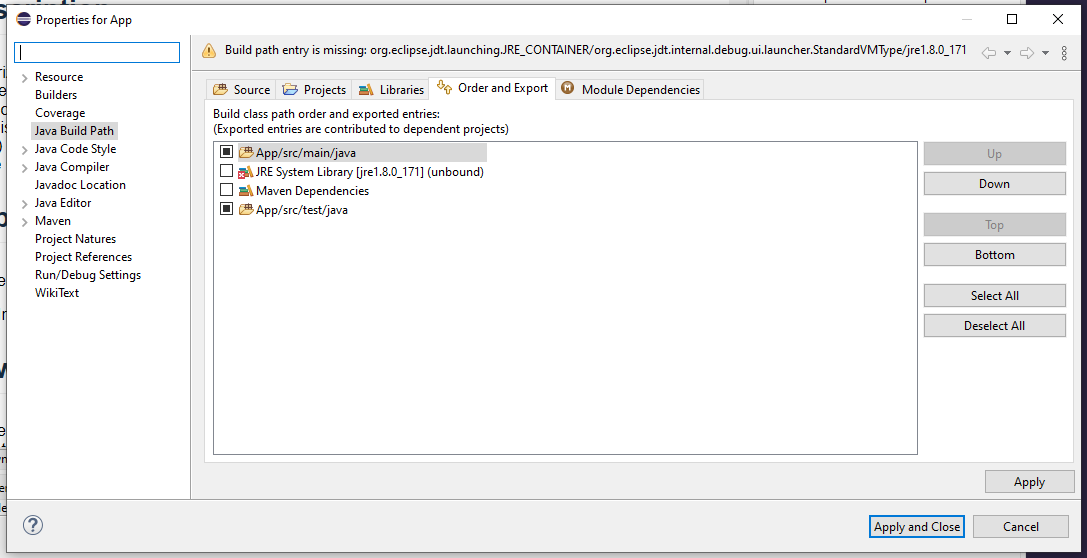
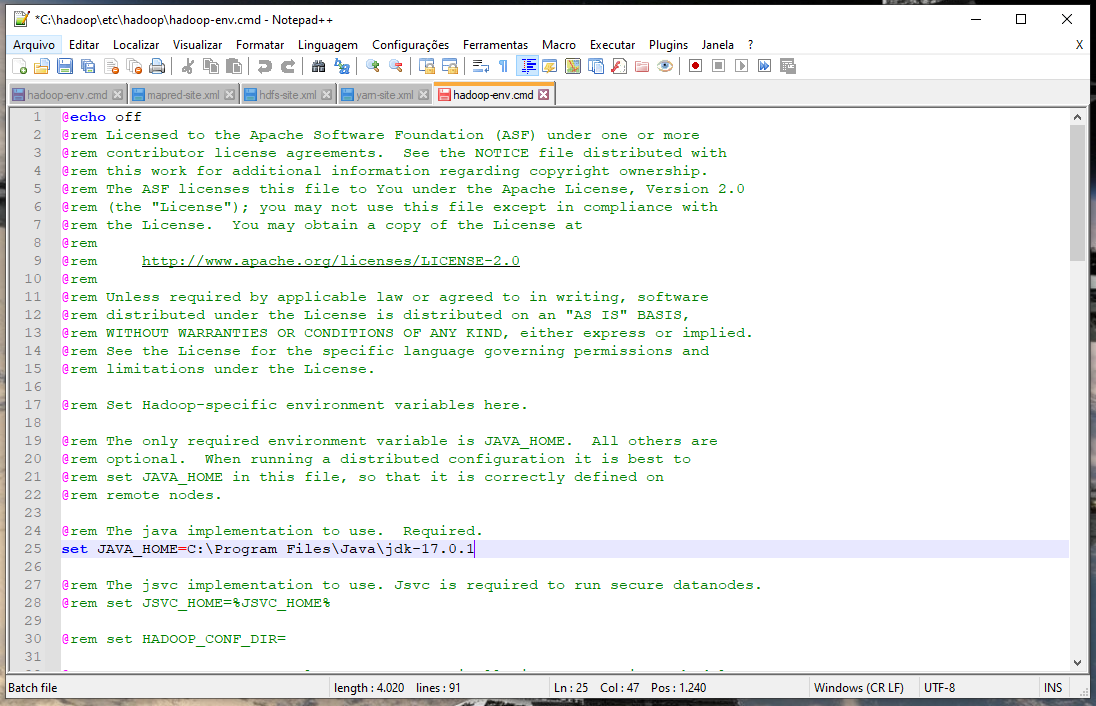
Você deve ter copiado esse projeto de outra máquina então seu projeto está configurado para usar uma versão específica do Java que você não tem instalada.
Ajusta as propriedades do projeto para usar o Java que você tem.
Please go to the project folder and run the command “mvn clean package -Dmaven.test.skip=true”, then we will get two archive files in the sub folder “target”, one is “JLibFM-0.1-SNAPSHOT-jar-with-dependencies.jar”. Now we can prepare the dataset. In the current version, only LibSVM format is supported. There is a Java class com.github.gaterslebenchen.libfm.examples.MovieLens1MFormater in this project.
(1) an example of Stochastic Gradient Descent (SGD) method:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/12/26 15:29:06 INFO SparkContext: Running Spark version 2.3.0
21/12/26 15:29:06 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/12/26 15:29:06 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:378)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:393)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:386)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116)
at org.apache.hadoop.security.Groups.<init>(Groups.java:93)
at org.apache.hadoop.security.Groups.<init>(Groups.java:73)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2464)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:292)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2486)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:930)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:921)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:921)
at com.packt.JavaDL.MovieRecommendation.EDA.ExploratoryDataAnalysis.main(ExploratoryDataAnalysis.java:21)
21/12/26 15:29:06 INFO SparkContext: Submitted application: Bitcoin Preprocessing
21/12/26 15:29:06 INFO SecurityManager: Changing view acls to: multi
21/12/26 15:29:06 INFO SecurityManager: Changing modify acls to: multi
21/12/26 15:29:06 INFO SecurityManager: Changing view acls groups to:
21/12/26 15:29:06 INFO SecurityManager: Changing modify acls groups to:
21/12/26 15:29:06 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(multi); groups with view permissions: Set(); users with modify permissions: Set(multi); groups with modify permissions: Set()
21/12/26 15:29:06 INFO Utils: Successfully started service 'sparkDriver' on port 60893.
21/12/26 15:29:06 INFO SparkEnv: Registering MapOutputTracker
21/12/26 15:29:06 INFO SparkEnv: Registering BlockManagerMaster
21/12/26 15:29:06 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
21/12/26 15:29:06 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
21/12/26 15:29:06 INFO DiskBlockManager: Created local directory at C:\Users\multi\AppData\Local\Temp\blockmgr-b24dfd21-248d-4231-b7ef-9aa06f52dd2a
21/12/26 15:29:06 INFO MemoryStore: MemoryStore started with capacity 4.6 GB
21/12/26 15:29:06 INFO SparkEnv: Registering OutputCommitCoordinator
21/12/26 15:29:06 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/12/26 15:29:06 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://DESKTOP-2S65B7B:4040
21/12/26 15:29:06 INFO Executor: Starting executor ID driver on host localhost
21/12/26 15:29:06 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 60894.
21/12/26 15:29:06 INFO NettyBlockTransferService: Server created on DESKTOP-2S65B7B:60894
21/12/26 15:29:06 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
21/12/26 15:29:06 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, DESKTOP-2S65B7B, 60894, None)
21/12/26 15:29:06 INFO BlockManagerMasterEndpoint: Registering block manager DESKTOP-2S65B7B:60894 with 4.6 GB RAM, BlockManagerId(driver, DESKTOP-2S65B7B, 60894, None)
21/12/26 15:29:06 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, DESKTOP-2S65B7B, 60894, None)
21/12/26 15:29:06 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, DESKTOP-2S65B7B, 60894, None)
21/12/26 15:29:06 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('temp/').
21/12/26 15:29:06 INFO SharedState: Warehouse path is 'temp/'.
21/12/26 15:29:07 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
Exception in thread "main" java.lang.reflect.InaccessibleObjectException: Unable to make field private transient java.lang.String java.net.URI.scheme accessible: module java.base does not "opens java.net" to unnamed module @480d3575
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354)
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at java.base/java.lang.reflect.Field.checkCanSetAccessible(Field.java:178)
at java.base/java.lang.reflect.Field.setAccessible(Field.java:172)
at org.apache.spark.util.SizeEstimator$$anonfun$getClassInfo$3.apply(SizeEstimator.scala:336)
at org.apache.spark.util.SizeEstimator$$anonfun$getClassInfo$3.apply(SizeEstimator.scala:330)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at org.apache.spark.util.SizeEstimator$.getClassInfo(SizeEstimator.scala:330)
at org.apache.spark.util.SizeEstimator$.visitSingleObject(SizeEstimator.scala:222)
at org.apache.spark.util.SizeEstimator$.org$apache$spark$util$SizeEstimator$$estimate(SizeEstimator.scala:201)
at org.apache.spark.util.SizeEstimator$.estimate(SizeEstimator.scala:69)
at org.apache.spark.sql.execution.datasources.SharedInMemoryCache$$anon$1.weigh(FileStatusCache.scala:109)
at org.apache.spark.sql.execution.datasources.SharedInMemoryCache$$anon$1.weigh(FileStatusCache.scala:107)
at org.spark_project.guava.cache.LocalCache$Segment.setValue(LocalCache.java:2222)
at org.spark_project.guava.cache.LocalCache$Segment.put(LocalCache.java:2944)
at org.spark_project.guava.cache.LocalCache.put(LocalCache.java:4212)
at org.spark_project.guava.cache.LocalCache$LocalManualCache.put(LocalCache.java:4804)
at org.apache.spark.sql.execution.datasources.SharedInMemoryCache$$anon$3.putLeafFiles(FileStatusCache.scala:152)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$listLeafFiles$2.apply(InMemoryFileIndex.scala:130)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$$anonfun$listLeafFiles$2.apply(InMemoryFileIndex.scala:128)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.listLeafFiles(InMemoryFileIndex.scala:128)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.refresh0(InMemoryFileIndex.scala:91)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.<init>(InMemoryFileIndex.scala:67)
at org.apache.spark.sql.execution.datasources.DataSource.tempFileIndex$lzycompute$1(DataSource.scala:161)
at org.apache.spark.sql.execution.datasources.DataSource.org$apache$spark$sql$execution$datasources$DataSource$$tempFileIndex$1(DataSource.scala:152)
at org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:166)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:392)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:239)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:227)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:174)
at com.packt.JavaDL.MovieRecommendation.EDA.ExploratoryDataAnalysis.main(ExploratoryDataAnalysis.java:28)
21/12/26 15:29:07 INFO SparkContext: Invoking stop() from shutdown hook
21/12/26 15:29:07 INFO SparkUI: Stopped Spark web UI at http://DESKTOP-2S65B7B:4040
21/12/26 15:29:07 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/12/26 15:29:07 INFO MemoryStore: MemoryStore cleared
21/12/26 15:29:07 INFO BlockManager: BlockManager stopped
21/12/26 15:29:07 INFO BlockManagerMaster: BlockManagerMaster stopped
21/12/26 15:29:07 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/12/26 15:29:07 INFO SparkContext: Successfully stopped SparkContext
21/12/26 15:29:07 INFO ShutdownHookManager: Shutdown hook called
21/12/26 15:29:07 INFO ShutdownHookManager: Deleting directory C:\Users\multi\AppData\Local\Temp\spark-64d1f0b7-e833-49b9-ad35-11df7a67ed02
Pelo jeito seu projeto usa o Hadoop mas você não tem o Hadoop instalado.
Talvez seja melhor você pedir ajuda para quem te passou esse projeto, vai ser difícil você avançar na tentativa e erro.