Estou usando a api iText para criar um arquivo PDF com os dados de um arquivo TXT. O arquivo TXT é um relatório retirado do sistema da empresa onde trabalho, no caso preciso criar o PDF mantendo o mesmo layout do arquivo TXT, pois se trata de dados com descrição e valores, porém quando estou criando o PDF usando o código abaixo esta formatação do layout é diferente. Ista diferença pode ser verificada nos arquivos em anexo.
Gostaria da ajuda de vocês pra saber se tem como gerar o PDF com o mesmo layout do TXT.
Desde já agradeço pela atenção!
try
{
FileReader reader = new FileReader("D:\\Slip\\3889.txt");
BufferedReader leitor = new BufferedReader(reader);
//criação do pdf // (Es, Dir,Sup,Inf)
Document document = new Document(PageSize.A4, 10, 10, 10, 10);
PdfWriter.getInstance(document, new FileOutputStream("D:\\Slip\\3889.pdf"));
document.open();
//Ler txt linha a linha
while(leitor.ready())
document.add(new Paragraph(leitor.readLine(),FontFactory.getFont(FontFactory.TIMES,8, Font.PLAIN,new Color(0,0,0))));
leitor.close();
document.close();
} catch (Exception e)
{
e.printStackTrace();
}
Renato, em vez de usar a fonte Times, que tem tamanhos de letras diferentes (uma letra “W” é mais gorda que uma letra “i”, e um espaço é bem magrinho também), use uma outra fonte.
Que fonte?
Consulte a documentação (dica: em vez de FontFactory.TIMES, deve ser algum outro valor. Costuma ser algo parecido com “COURIER” mas não tenho a documentação aqui comigo).
Resolvido com a mudança da fonte, valew Entanglement.
Kadu agradeço pelo retorno. Sobre encontrar jeito melhor vai depender da necessidade de cada um. Usando a API iText, com o código acima, apenas troquei a fonte como sugestão do Entanglement e ja vai me atender. Desta forma consigo não epenas converter para PDF más posso incluir informações que achar necessário, pois estou lendo o TXT linha a linha e posso manipuar as informações.
Mas e quando eu preciso do contrário? Ou seja, tenho um arquivo .pdf e preciso converter para txt mantendo a formatação
//Carregando o PDF
PdfReader pdfReader = new PdfReader("D:/CLIENTES/TESTE_PDF/111.pdf");
Document doc = new Document(PageSize.A4, 10, 10, 10, 10);
OutputStream os = new FileOutputStream("D:/CLIENTES/out.pdf");
PdfWriter.getInstance(doc, os);
doc.open();
String s = "";
//Criando o TXT
FileWriter arq =new FileWriter(new File("D:/CLIENTES/TESTE_PDF/Arquivo.txt"));
//Extraindo de página em página e jogando numa String
for (int i = 1; i <= pdfReader.getNumberOfPages(); i++) {
s = s.concat(PdfTextExtractor.getTextFromPage(pdfReader, i) + "\n\n");
s = s.replace("−","-");
arq.write(s);
}
arq.close();
Peço desculpas pelo código bem sujinho aí, mas é apenas um teste !
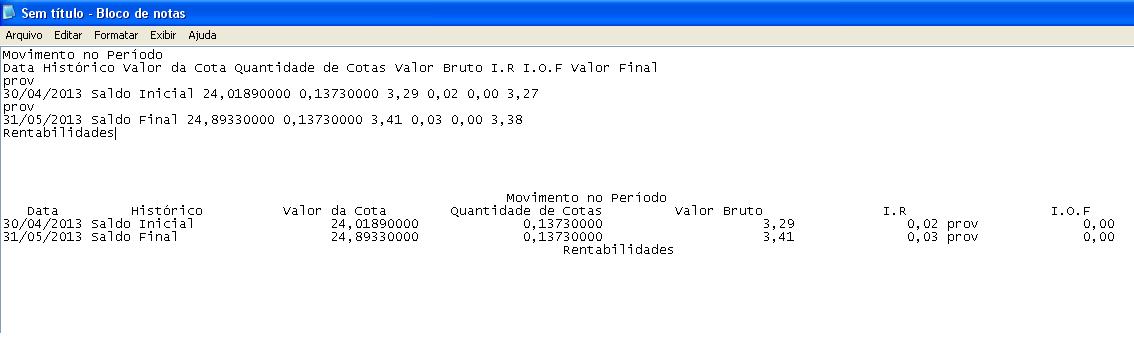
Então amigo, também tenho esse pensamento, porém, utilizando esse meu código de teste gerei o seguinte arquivo txt:
Movimento no Período
Data Histórico Valor da Cota Quantidade de Cotas Valor Bruto I.R I.O.F Valor Final
prov
30/04/2013 Saldo Inicial 24,01890000 0,13730000 3,29 0,02 0,00 3,27
prov
31/05/2013 Saldo Final 24,89330000 0,13730000 3,41 0,03 0,00 3,38
Rentabilidades
E utilizando um software chamado PDF Text Reader o resultado foi esse:
Movimento no Período
Data Histórico Valor da Cota Quantidade de Cotas Valor Bruto I.R I.O.F Valor Final
30/04/2013 Saldo Inicial 24,01890000 0,13730000 3,29 0,02 prov 0,00 3,27
31/05/2013 Saldo Final 24,89330000 0,13730000 3,41 0,03 prov 0,00 3,38
Rentabilidades
Que é a formatação exata do arquivo .pdf original e exatamente o que eu preciso no meu arquivo .txt
Alguém sabe como eu posso reproduzir este mesmo resultado?
Entendi. É que o programa que gerou o PDF posicionou os campos no PDF não exatamente na mesma sequência em que aparecem na tela.
Como o PDF é um formato de visualização e impressão, não de transferência de dados, volta e meia ocorre isso (um programa pode dispor o texto da direita para a esquerda e de baixo para cima mas criar um PDF que o mostra da esquerda para a direita e de cima para baixo.
O programa que você usou (PDF Text Reader) leva isso em conta, mas o PdfReader do iText não leva isso em conta. Por isso é que você pode ter essas diferenças.
Preciso pegar o texto de um determinado pdf e a partir desse texto gerar um arquivo .TXT. Já fiz isso e consigo levar todo o texto do pdf, linha a linha para o arquivo txt que eu criei. O problema é que com a API IText eu perco a referência de layout (a disposição dos dados).
Então…rs hoje utilizamos o software PdfTextReader e ele trata a disposição dos campos… faz o trabalho perfeitamente. Mas quero encontrar a solução “dentro de casa”.
Vou continuar fuçando e se eu avançar em algum aspecto com certeza irei postar aqui !