Boa tarde, pessoa!
Estou precisando de uma ajudinha aqui, fiz um script conforme pesquisei e não está dando certo, o problema é o seguinte:
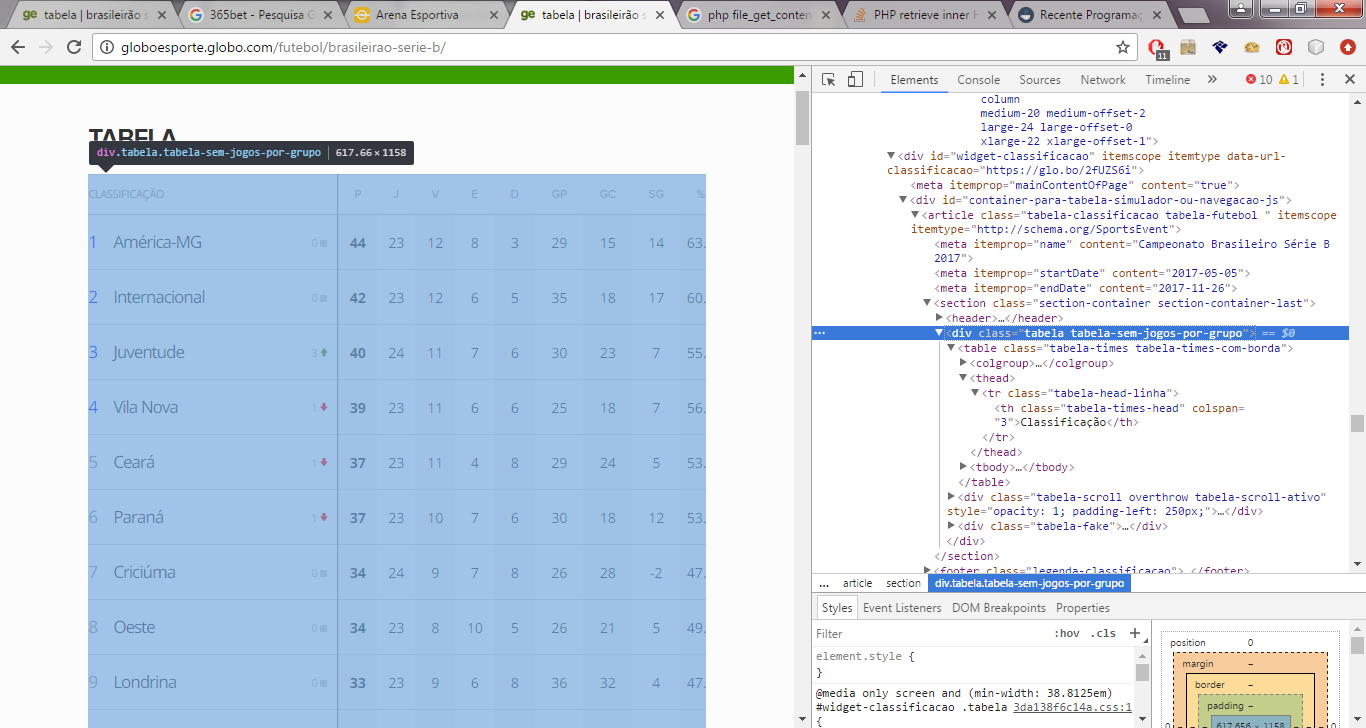
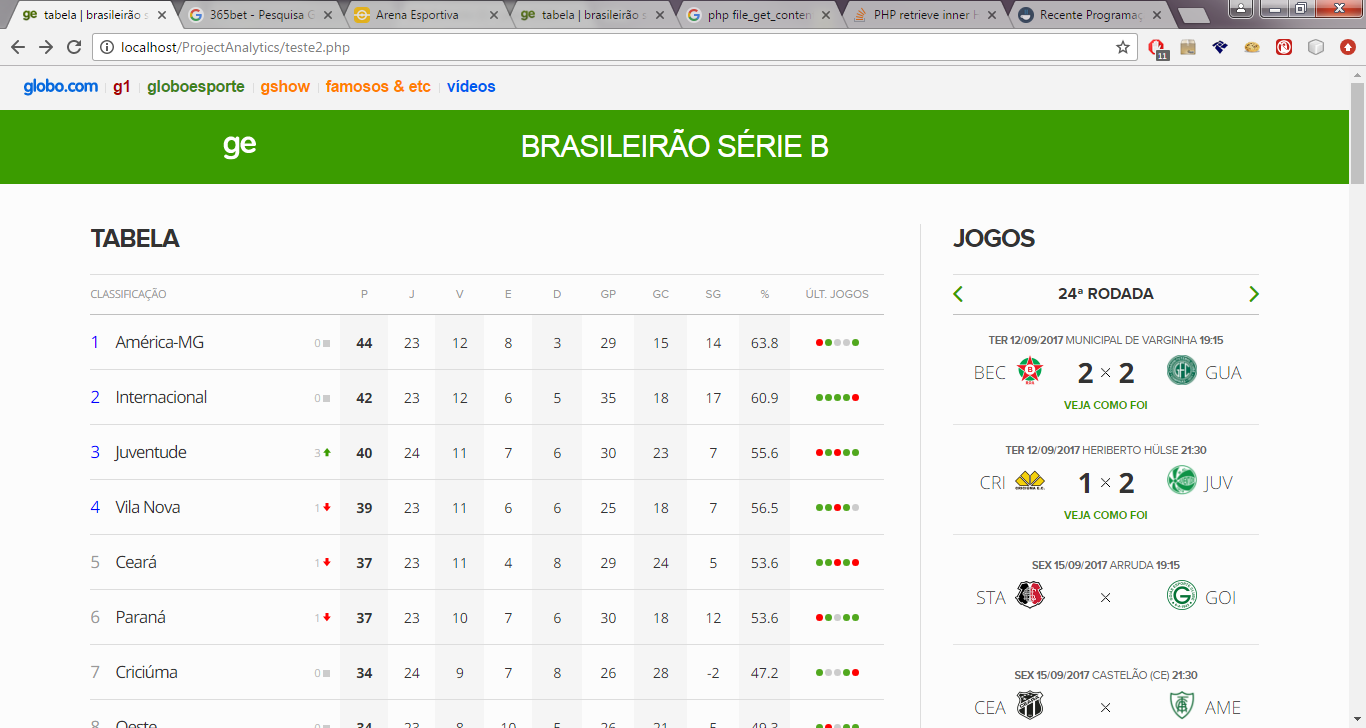
Estou tentando capturar uma div que conta no site do http://globoesporte.globo.com , só que quando tenho o retorno, ele exibe a tela toda da página, e eu só quero a div onde consta a tabela de classificação, ele deve vim de acordo como está no site do globoesporte, com seus devidos css.
Preciso somente deste trecho:
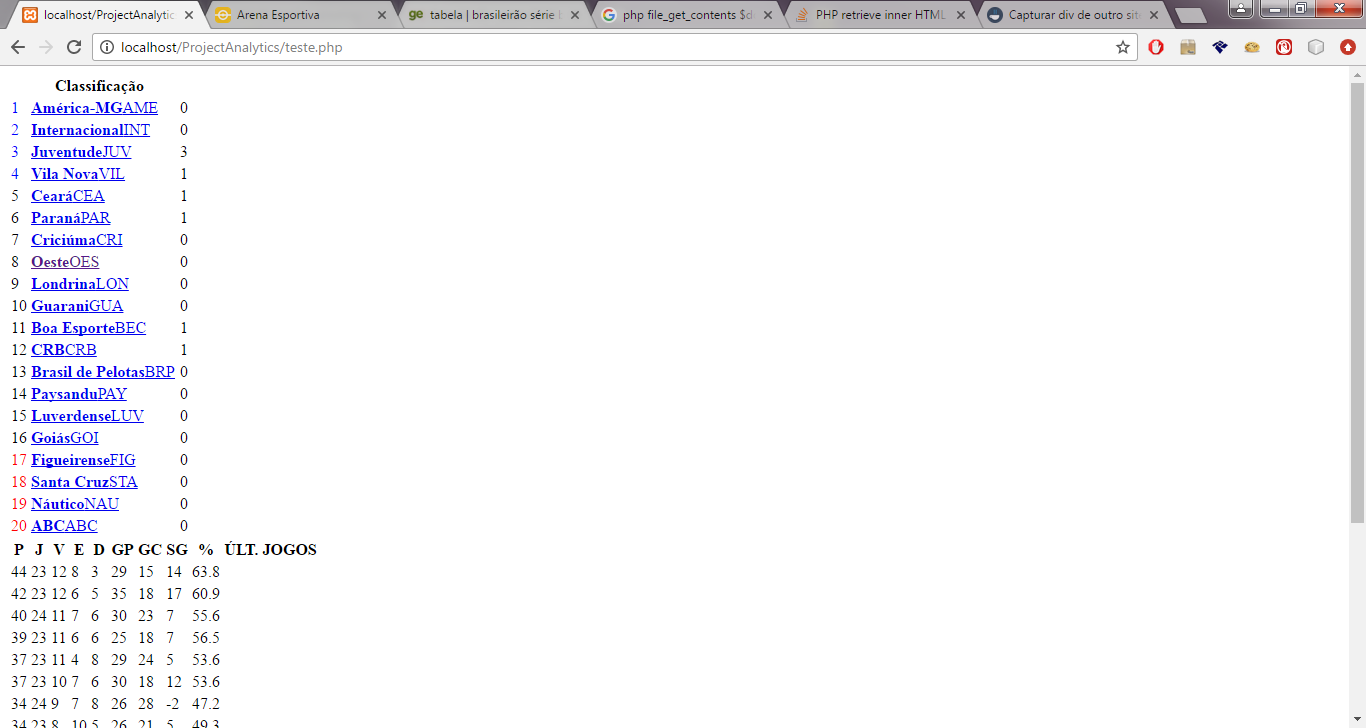
e ele está me trazendo o seguinte:
este é o meu código:
<?php
libxml_use_internal_errors(true);
$proxy = 'xxxxxxxxxx';
$auth = base64_encode("xxxxxxx:xxxxxxx");
$url = "http://globoesporte.globo.com/futebol/brasileirao-serie-b/";
$aContext = array(
'http' => array(
'proxy' => 'tcp://' . $proxy,
'request_fulluri' => true,
'header' => "Proxy-Authorization: Basic $auth"
),
);
$cxContext = stream_context_create($aContext);
$sFile = file_get_contents("http://globoesporte.globo.com/futebol/brasileirao-serie-b/", False, $cxContext);
echo $sFile;
libxml_use_internal_errors(false);
?>
Sem um identificador na div fica dificil… você pode colocar o html resgatado no objeto DOM e tentar manipular através de xpath…
php, dom
Algo nesse sentido…
$dom = new DOMDocument();
$dom->loadHtml($sFile);
$array_divs = $dom->getElementsByTagName('div');
...
Já tentei dessa forma, ai ele só trás texto.
tentei esse também:
libxml_use_internal_errors(true);
$ch = curl_init();
$proxy = 'proxy.sec.ba.gov.br:3128';
$proxyauth = 'yan.santos:Pl@ymoregame6';
$header = "X-Forwarded-For: {$_SERVER['REMOTE_ADDR']}";
curl_setopt($ch, CURLOPT_URL, "http://globoesporte.globo.com/futebol/brasileirao-serie-b/");
curl_setopt($ch, CURLOPT_HTTPHEADER, array($header));
curl_setopt($ch, CURLOPT_PROXY, $proxy);
curl_setopt($ch, CURLOPT_PROXYUSERPWD, $proxyauth);
//curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FILETIME, true);
$output = curl_exec($ch);// acessar URL
$response_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);// Pegar o código de resposta
if ($response_code == '404') {
die('Erro!');
} else {
$doc = new DOMDocument();
//$doc->formatOutput = true;
$doc->loadHTML($output);
$xpath = new DOMXpath($doc);
$elemento = $xpath->query( '//div[@class="tabela tabela-sem-jogos-por-grupo"]' )->item(0)->nodeValue;
echo $elemento;
//->item(0)->nodeValue
}//end else
libxml_use_internal_errors(false);
Você precisa pegar o nó/elemento por completo, ao usar nodeValue você está pegando o conteúdo e não a div inteira, tente salvando como html sem usar nodeValue…
$xpath = new DOMXpath($doc);
$elemento = $xpath->query( '//div[@class="tabela tabela-sem-jogos-por-grupo"]' )->item(0);
$div = $doc->saveHTML($elemento);
Veja a documentação
http://php.net/manual/pt_BR/domdocument.savehtml.php
Dessa forma ele trouxe, mas ele não veio com a tabela formatada de acordo como o site.
Não virá porque você não tem os css/js… por isso que antes funcionava, você trazia a página inteira, precisa incluí-los no dom também… além do mais, você só pediu a div
como faço para incluir no DOM ?
Fazendo outros $path->query…