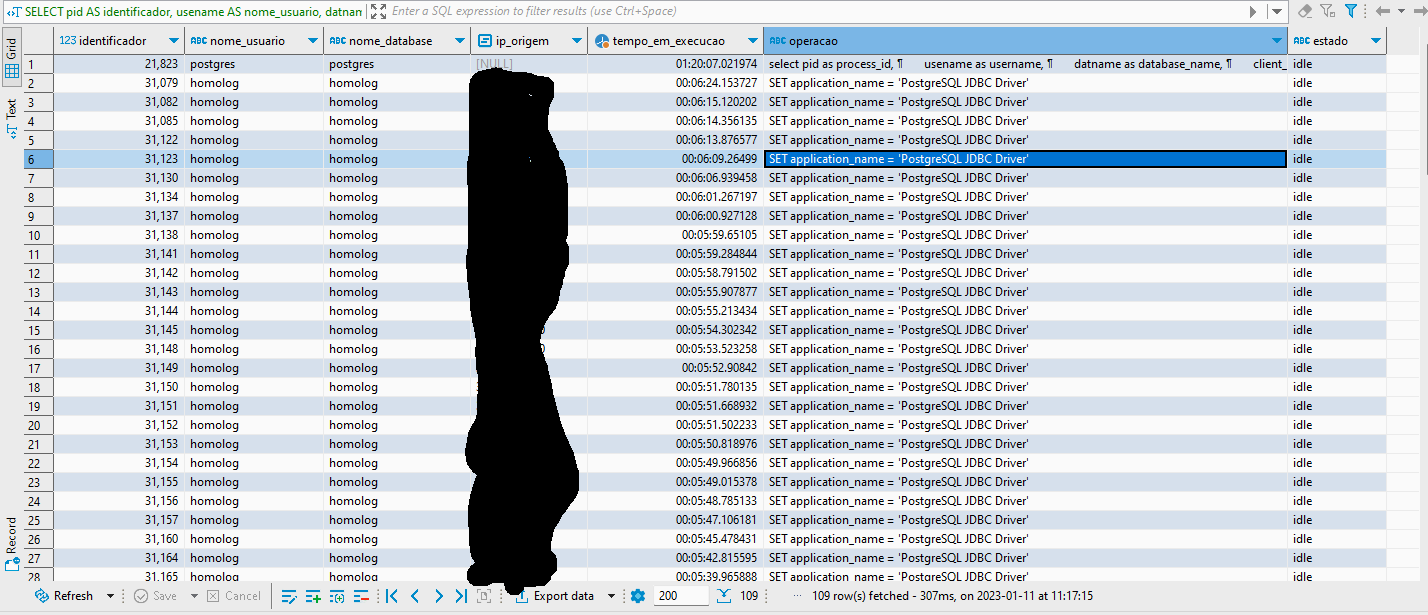
Sistema funciona normal, mas quando vou pelo DBeaver, não consigo conectar no banco de dados e mostra esta mensagem FATAL: sorry, too many clients already
No arquivo postgresql.conf, tem o parametro: shared_buffers, está com 900MB.
Sistema é spring-boot
no properties está assim:
spring.datasource.driverClassName=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://xxxxx
spring.datasource.username=xxxxx
spring.datasource.password=xxxxx
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=false
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.PostgreSQLDialect
spring.jpa.hibernate.ddl-auto=none
O que mais preciso fazer ?
Isso parece que vc ultrapassou o limite de conexões abertas simultaneamente com o banco
1 curtida
Você pode tentar mitigar configurando um pool de conexões nas aplicações cliente que acessam essa base de dados!
Por ser uma aplicação Spring você consegue usar as configurações que o Hikari oferece, se não me engano, o Hikari vem junto com a dependência do Spring Data.
Exemplo:
spring:
datasource:
url: ${url}
username: ${username}
password: ${password}
hikari:
auto-commit: false
connection-timeout: 250
max-lifetime: 600000
maximum-pool-size: 20
minimum-idle: 10
pool-name: master
2 curtidas
Sim. Aumentei para 200. Chega a 109 conexões abertas.
Mas como saber aonde esta o gargalo no sistema ?
Fiz o que vc disse.
Mas não adiantou, pois tem conexões abertas que não estão sendo fechadas.
Ficou assim:
spring.datasource.driverClassName=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://${DATABASE_HOSTNAME}:${DATABASE_PORT}/${DATABASE_NAME}
spring.datasource.username=${DATABASE_USERNAME}
spring.datasource.password=${DATABASE_PASSWORD}
spring.datasource.hikari.auto-commit=false
spring.datasource.hikari.connection-timeout=250
spring.datasource.hikari.max-lifetime=600000
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.pool-name=master
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=false
sspring.jpa.properties.hibernate.dialect=org.hibernate.dialect.PostgreSQLDialect
spring.jpa.hibernate.ddl-auto=none
Exemplos de Repository que trabalho
@Repository
public interface ArquivoExemploRepository extends JpaRepository<ArquivoExemplo, String> {
@Query(value = "SELECT e FROM ArquivoExemplo e WHERE (e.tipoArquivoExemplo = :tipoArquivoExemplo) AND (e.statusDoRegistro = 'ATIVO') ")
Optional<ArquivoExemplo> buscaPorTipo(@Param("tipoArquivoExemplo") TipoArquivoExemploEnum tipoArquivoExemplo);
}
no service, faço o seguinte
package br.com.ghnetsoft.forca_venda.pessoa.service;
import static br.com.ghnetsoft.principal.enuns.StatusDoRegistroEnum.INATIVO;
import static br.com.ghnetsoft.principal.enuns.TipoArquivoImportacaoEnum.ARQUIVO_EXEMPLO;
import java.io.IOException;
import java.security.Principal;
import java.util.Collection;
import java.util.Optional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.multipart.MultipartFile;
import br.com.ghnetsoft.forca_venda.model.Arquivo;
import br.com.ghnetsoft.forca_venda.model.ArquivoExemplo;
import br.com.ghnetsoft.forca_venda.pessoa.preencher.ArquivoPreencher;
import br.com.ghnetsoft.forca_venda.repository.ArquivoExemploRepository;
import br.com.ghnetsoft.principal.dto.ArquivoDTO;
import br.com.ghnetsoft.principal.enuns.TipoArquivoExemploEnum;
import br.com.ghnetsoft.principal.exception.GeralException;
import br.com.ghnetsoft.principal.service.PrincipalService;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Service
public class ArquivoExemploImportarServico extends PrincipalService {
private static final long serialVersionUID = -7065923051038009844L;
@Autowired
private transient ArquivoExemploRepository repository;
@Autowired
private ArquivoService arquivoService;
@Autowired
private ArquivoPreencher arquivoPreencher;
@Transactional
public ArquivoExemplo salvar(ArquivoExemplo entidade) {
log.info("salvar entidade - antes: " + entidade.toString());
entidade = repository.save(entidade);
log.info("salvar entidade - depois: " + entidade.toString());
return entidade;
}
@Transactional
public void importacao(final Collection<MultipartFile> files, final String tipoArquivoExemplo, final Principal principal) {
try {
log.info("importacao - tipoArquivoExemplo: " + tipoArquivoExemplo);
final TipoArquivoExemploEnum tipoArquivoExemploEnum = TipoArquivoExemploEnum.buscaTipoArquivoExemploEnum(tipoArquivoExemplo);
if (tipoArquivoExemploEnum == null) {
throw new GeralException("Tipo de arquivo de exemplo inválido !");
}
final Optional<ArquivoExemplo> arquivoExemploExiste = repository.buscaPorTipo(tipoArquivoExemploEnum);
ArquivoExemplo entidade;
if (arquivoExemploExiste.isPresent()) {
entidade = arquivoExemploExiste.get();
entidade.setStatusDoRegistro(INATIVO);
salvar(entidade);
final Arquivo arquivo = entidade.getArquivo();
arquivo.setStatusDoRegistro(INATIVO);
arquivoService.salvar(arquivo);
}
entidade = ArquivoExemplo.builder().build();
for (final MultipartFile file : files) {
final Arquivo arquivo = arquivoService.salvar(file, ARQUIVO_EXEMPLO);
entidade.setArquivo(arquivo);
entidade.setTipoArquivoExemplo(tipoArquivoExemploEnum);
salvar(entidade);
}
} catch (final IOException e) {
throw new GeralException("Erro ao salvar arquivo !");
}
}
public ArquivoDTO buscaPorTipo(final String tipoArquivoExemplo) {
log.info("buscaPorTipo - tipoArquivoExemplo: " + tipoArquivoExemplo);
final TipoArquivoExemploEnum tipoArquivoExemploEnum = TipoArquivoExemploEnum.buscaTipoArquivoExemploEnum(tipoArquivoExemplo);
if (tipoArquivoExemploEnum == null) {
throw new GeralException("Tipo de arquivo de exemplo inválido !");
}
final Optional<ArquivoExemplo> arquivoExemploExiste = repository.buscaPorTipo(tipoArquivoExemploEnum);
if (!arquivoExemploExiste.isPresent()) {
throw new GeralException("Não existe arquivos para este tipo !");
}
return arquivoPreencher.preencherDto(arquivoExemploExiste.get().getArquivo());
}
}
Consulta realizada no banco de dados
SELECT
pid AS identificador,
usename AS nome_usuario,
datname AS nome_database,
client_addr AS ip_origem,
now() - query_start AS tempo_em_execucao,
query AS operacao,
state AS estado
FROM
pg_stat_activity
ORDER BY
query_start;
Como descobrir e como fazer para ajustar as conexões abertas sem a necessidade ?
A ideia do pool de conexões é gerenciar o limite de conexões entre outras coisas em relação ao seu banco de dados por instância de aplicação, o trabalho de criar e fechar conexões é de responsabilidade do entityManager que roda por baixo dos panos no spring data!
O exemplo de configuração que te mandei ele mantém um pool de 10 conexões em idle, o que significa que estas conexões estão abertas e adormecidas esperando alguma operação com o banco para que possam ser utilizadas, o conceito de conexão em idle traz o ganho de você não precisar toda vez que for exercer alguma operação com o banco ter o custo de tempo de abrir uma conexão para que depois possa utilizar.
E o tamanho do pool em 20 diz que por instância a aplicação pode ter no máximo 20 conexões ativas ao mesmo tempo (10 idle + 10 sob demanda).
Lembrando, isso não é a solução, é uma forma de iniciar a mitigação do problema e inclusive é uma boa prática!
Agora se você quer à todo custo deixar sua aplicação sem nenhuma conexão “adormecida”, teoricamente falando, bastaria zerar o valor de conexões em idle, porém, vale ressaltar que o custo de ficar criando conexão a todo instante para cada operação que for realizar pode ser mais agravante do que ter conexões prontas e adormecidas para uso.
1 curtida
Então para cada aplicação que eu tenho para este banco, ele tem estas 20 conexões ativas. o que é mostrado nesta consulta SELECT * FROM pg_stat_activity; no banco de dados.
Se tenho 10 sistemas conectadas a este banco, sempre vai ter 100 conexões ativas e adormecidas ?
Exatamente!
Esse número 10 (idle) é um número mágico, da mesma forma que o 20 (sob demanda) também é.
Você pode adaptá-los para a sua realidade e necessidade!
O importante é sempre ter em mente que a quantidade de conexões idle é: valor definido para idle x número de instâncias.
Da mesma forma o máximo de conexões ativas que você pode atingir é: valor definido para máximo x número de instâncias.
1 curtida