Desenhando o seguinte banco de dados para um aplicativo de mensagens (estilo WhatsApp)
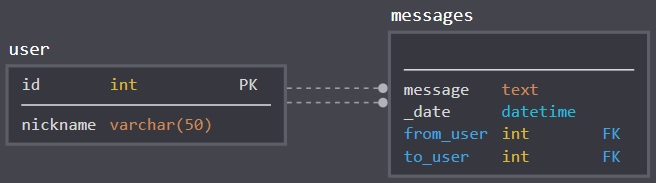
Me deparei com um “problema”: Imaginando que este aplicativo seja usado por milhares de usuários, cada usuário pode manter dezenas de conversas e cada conversa pode ter cetenas de mensagens, a tabela “messages” guardaria um volume absurdo de dados.
Tenho as seguintes dúvidas:
- Isto causaria problemas sérios de desempenho?
- Há outra forma de modelar este banco para solucionar este problema?
Obs: qualquer informação que puderem acrescentar pode ser útil.
Podem ter milhares de dados guardados, mas você vai consultar do banco as informações sob demanda do usuário, usando paginação de x mensagens enquanto o usuário fizer rolagem. Atenção sempre na otimização.
1 curtida
Isto é óbvio amigo, mas ainda sim o desempenho seria comprometido, pois teria que selecionar registros que satisfaçam tais condições dentro de centenas de milhares de mensagens.
E qual a complicação nisso?
As aplicações que existem hoje já fazem isso, WhatsApp, Instagram, Facebook, são usuários do mundo inteiro movimentando, tem ideia da quantidade de dados e informação?!
Não faz diferença a quantidade de informação que você tem armazenada em sua base de dados, e sim a maneira como você trata essa informação para apresentá-la ao usuário, compreende?
Um ponto a se destacar para que você possa avaliar em questão de desempenho é o uso de banco de dados NoSQL, que trabalha movimentando documentos.
Então seja mais específico. A questão ficou como se nunca tivesse estudado e trabalhado com banco de dados.
Trabalho com uma base de milhões de registros no Oracle e a aplicação não tem problemas de performance só por ter milhares de registros armazenados no banco. Ao estudar sobre otimização, vai ver sobre tunning, uso de índices, etc. Você não vai carregar os milhoes de registros ou fazer o banco percorrer esses milhoes. Esse é o básico sim, mas sua questao também está básica, não fez nem um teste de stress pra chegar com um problema real.
Não existe complicação nisso, é só que não conheço o funcionamento interno dos algoritmos de um SGBD. Presumi que quanto mais registros na tabela, mais lenta é uma consulta como o “SELECT”.
Ideal seria começar por um conteúdo mais teórico. Mas só pra ilustrar na prática de forma básica com um SGDB popular: https://www.devmedia.com.br/otimizacao-de-banco-de-dados-no-mysql/294
Vários fatores podem afetar o desempenho de uma query, mas são coisas que já são contornáveis, utilizando os conceitos de índices, paginação, tunning e muitas outras coisas igual o amigo @javaflex te citou em uma resposta acima.
2 curtidas
@thewesker, não causaria problemos sérios e por isso não teria uma maneira exata de como fazer a modelagem para prever os “problemas sérios”, mas existem boas praticas, muitas por sinal, para melhorar o empenho das consultas como já citado acima.
Levando em conta apenas a modelagem, em banco relacional, eu criaria uma tabela nomeada “conversa”, que ligaria os usuarios que estão na conversa, e ligaria a tabela conversa com mensagens. Na minha visão melhoria a leitura de quem vai poder usar futuramente essas tabelas, tanto como manutenção quanto a evolução de novas funcionalidades.
Havia pensado nisso quando imaginei conversas em grupo. Obrigado pela sugestão!
1 curtida
Só algumas perguntas para levar em consideraçao:
-
Você está fazendo isso para aprender ou para atender uma necessidade real ou cliente?
-
Se é necessidade real, já procurou alguma soluçao pronta para chats? Produto ou framework?
-
Você precisa armazenar todas as mensagens para sempre? Pode apagá-las depois de lidas por exemplo?
O Whatsapp, por exemplo, acredito que nem armazenam mensagens em banco, depois de enviadas para o cliente, eles nao mantém a cópia.
O Slack tem uma política de manter mensagens por um determinado período (6 meses, por exemplo).
