Calma, vou te fazer compreender melhor o cenário…
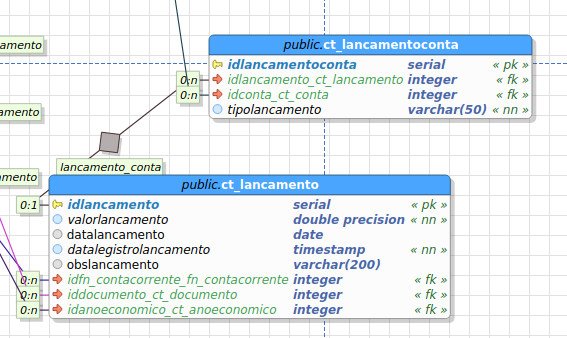
Bom dia amigo, é o seguinte, eu tenho uma tabela lancamento que tem relação com uma tabela lancamentoconta conforme mostra a figura abaixo
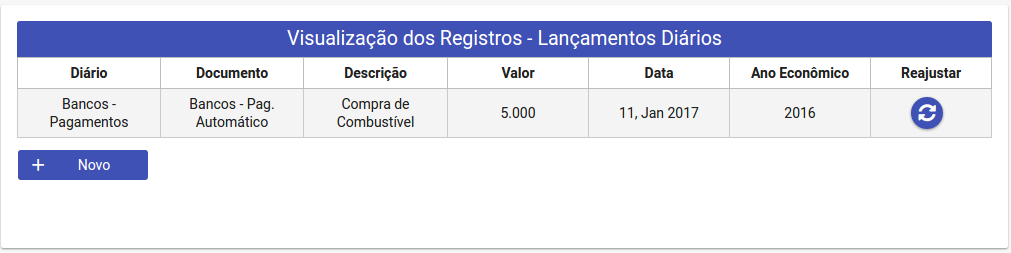
Agora, aqui nessa outra imagem eu tenho uma lista dos lançamentos essa lista vem da minha ManagedBean Lançamento.
Resultado
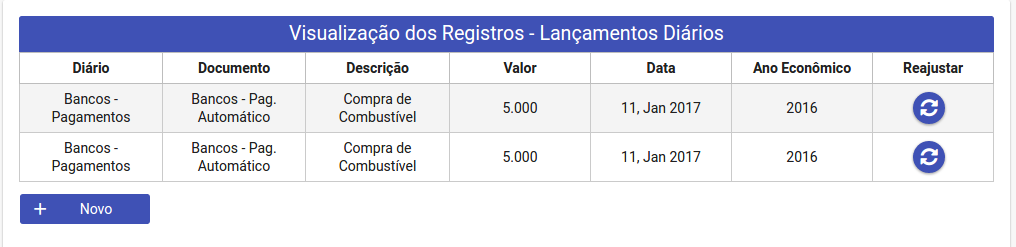
Neste outro cenário, eu tenho a mesma tabela a ser preenchida com uma lista de lençamentocontas como ela tem relação com a tabela lançamento a partir do idlancamento eu pego todos os atributo da tabela lançamento. Porém utilizando uma lista de lançamentoconta eu terei os registros duplicados porque a operação de lançamento envolve duas contas(débito e credito) logo idlancamento na tabela lancamentoconta é duplicado mas com a mesma informação. Vê a imagem abaixo
![]()
Resiltado usando uma lista do tipo lançamentoconta
OBS.: Eu pretendo ter uma lista do tipo lancamentoconta sem os itens repetidos.
Abraços!
Opa Bruno, bom dia!
Acho que agora compreendi melhor o problema, obrigado! Essa query aqui talvez funcione para você:
SELECT
DISTINCT(ctLancamentoConta.<ATRIBUTO_PARA_DISTINGUIR>) ctLancamentoConta
FROM CtLancamento ctLancamento
JOIN p.ctLancamentoConta WHERE ctLancamento = :lancamento
Lendo meio de trás pra frente, essa query vai:
-
Fazer um join de Ct_Lancamento com Ct_LancamentoConta, somente para o teu Ct_Lancamento específico (por causa do where com a comparação de CtLancamento). Eu acho que você tem o objeto CtLancamento específico ali no teu bean, certo? O mesmo para o qual você quer listar os lancamentos diários. Se tem, você pode fazer assim:
TypedQuery<CtLancamentoConta> q = em.createQuery(stringComAQueryAliDeCima) .setParameter("lancamento", CtLancamentoQueTemNoBean); return q.getResultList(); -
A respeito do distinct, cabe a você decidir qual é o parâmetro que você quer usar para distinguir duas entidades. O teu exemplo dos dois lancamentos “iguais” não é muito bom, porque todos os atributos deles são iguais. Você tem que dizer o que caracteriza um lancamento repetido. É o diário? O documento? O valor? A data?
Eu não tenho certeza, mas acho que você pode passar mais de um parâmetro no distinct.
Outra coisa, eu estava pesquisando aqui e descobri que talvez essa query não te retorne exatamente a lista de CtLancamentoConta, mas os atributos que você selecionar no DISTINCT. Eu to sem ter como testar aqui. Tenta e me diz o que aconteceu!
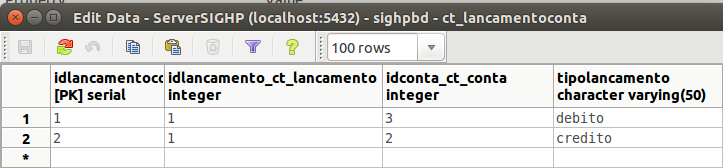
Ok, vou testar. Mas vale dizer que o caracteriza um lançamento repetido é o idLançamento que está na tabela lançamentoconta, como um lançamento em contabilidade envolve duas contas então o idlançamento na tabela lançamentoconta se repete duas vezes porque temos uma conta a debitar e outra a creditar. Mas Ivbarbosa vamos fazer o seguinte, vamos supor que eu quero uma query que me retorna todos os elementos da tabela lancamentoconta usando o distinct no idlancamento porque é o mesmo. Vê essa imagem dos dados da tabela idlancamentoconta.
Nota que nesta tabela o idlancemento está repatido pois eu quero uma query que me traz todos os itens dessa tabela lancamentoconta mas usando o distinct no idlancamento. OBS. Esquece a tabela lancamento.
Desde já eu agradeço o teu apoio
Deste uma olhada?
Tentou fazer assim?
SELECT DISTINCT(lc.idLancamento_ct_lancamento) lc
FROM LancamentoConta lc
O problema é que eu não tenho certeza se as queries com DISTINCT retornam a entidade ou apenas uma lista com o atributo que você quer distinto. Você sabe o que acontece? Não tenho como testar por enquanto.
Se não funcionar, confesso que não sei o que fazer para conseguir obter o resultado que você quer, vou ter que dar uma estudada mais tarde porque to realmente curioso pra descobrir como é que se faz isso. Assim que eu descobrir eu respondo pra ti.
Bruno,
Depois de dar uma estudada, eu vi que o DISTINCT no JPA funciona exatamente como no SQL. Você aplica DISTINCT num certo campo (ou coluna), e aquela coluna apenas é retornada. Por exemplo
SELECT DISTINCT(pessoa.nome) FROM Pessoa p
Retorna apenas os nomes distintos. Sendo nome um campo que não é chave primária, não dá para eliminar duplicatas com ele. O que eu te falei antes para tentar fazer está completamente errado.
O que tem como fazer também, é o seguinte (que você já tentou)
SELECT DISTINCT(p) FROM Pessoa p
O que é utilizado aqui para fazer o DISTINCT é a chave primária de Pessoa.
No teu caso, você quer uma lista de lançamentos distinguidos pelo nome do negócio ali, o Documento, ou a Descrição, que acho que não são chaves primárias.
Até agora eu ainda não descobri como buscar dessa maneira que você quer. Algumas alternativas são:
-
GROUP BYna coluna que você quer única, montando a lógica de agrupamento na query - Filtrar na aplicação, e não no DB
Ok, mas ultrapassei essa situação de uma outra forma mas preciso mesmo dessa solução. vou ler mais, olha tem um outro cenário… vou te marcar no tópico.
Abraços
Acabei de pensar numa solução com o GROUP BY.
A ideia da query é a seguinte: você vai selecionar os IDs com nomes únicos de lançamento, assim:
SELECT MIN(l.id) FROM Lancamento l GROUP BY l.nome
Beleza? Essa query vai te retornar apenas 1 ID para cada nome de lancamento. Você vai utiliza-la como subquery na query principal, assim:
SELECT lanc FROM Lancamento lanc WHERE lanc.id IN (SELECT MIN(l.id) FROM Lancamento l GROUP BY l.nome)Ok, vou implementar depois te dou um toque.
Tá com cara de gambiarra, não sei porque hahahahaha
Mas acredito que vá funcionar.
ya kkkk